






One of the biggest challenges in robotics research has always been helping AI truly understand the 3D world. Most Visual-Language-Action (VLA) models are built on pre-trained vision-language models (VLMs), which only learn from 2D image–text data. That means they lack the depth perception and spatial reasoning needed for real-world tasks.
Until now, many attempts to fix this problem have relied on explicit depth inputs or additional sensors. While effective, those methods are noisy, expensive, and hard to deploy at scale.
The Breakthrough: Evo-0
Researchers from Shanghai Jiao Tong University and the University of Cambridge introduced Evo-0, a lightweight method that injects 3D geometric priors directly into VLA models. Unlike traditional approaches, Evo-0 doesn’t require extra sensors or explicit depth maps.
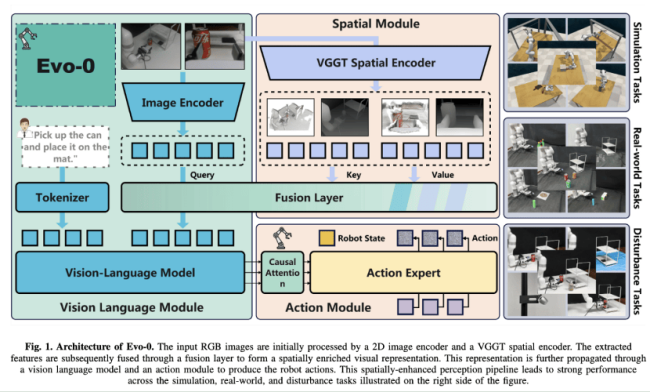

Instead, Evo-0 uses the Visual Geometry Grounded Transformer (VGGT) to extract 3D structure from multi-view RGB images. These 3D tokens are then fused with 2D vision tokens via a cross-attention mechanism, creating a richer, spatially aware representation.
Why It Matters
By blending 2D and 3D perception, Evo-0 allows robots to interpret object layouts, spatial structures, and depth relationships far more accurately. This translates into:
-
31% higher success rates compared to OpenVLA-OFT.
-
15% improvement over the baseline Pi0 model in RLBench simulations.
-
28.9% boost in real-world robotic tasks, including plug insertion, shelf placement, dense grasping, and handling transparent objects.
-
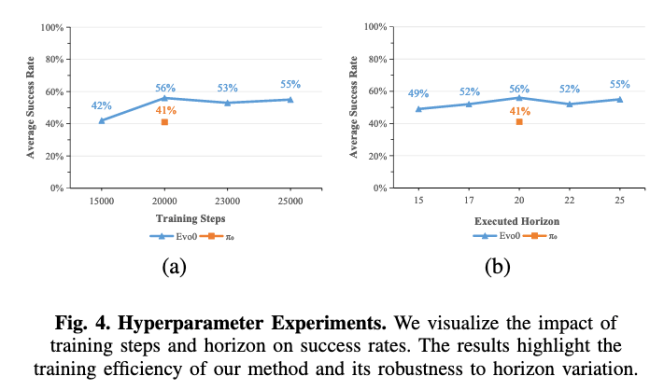
Higher training efficiency: Evo-0 trained with 15k steps already outperformed Pi0 trained with 20k steps.

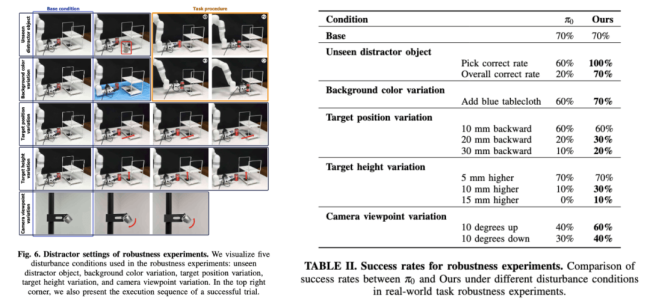
Tested in Both Lab and Real-World Settings
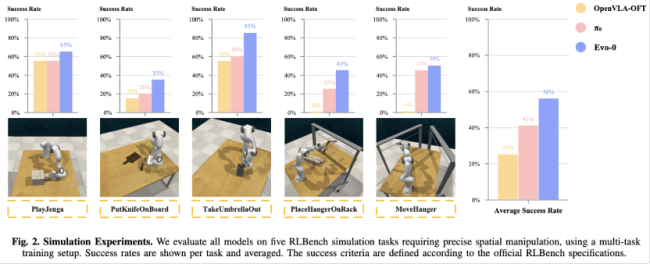
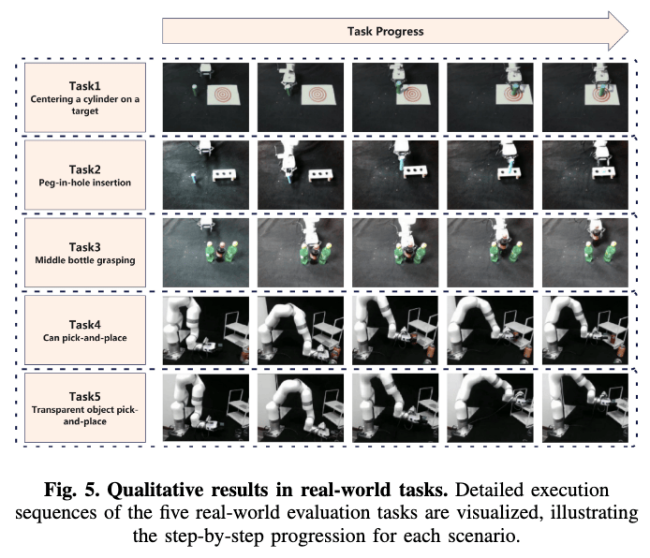


The research team validated Evo-0 across 5 RLBench simulation tasks and 5 real-world robotic tasks that demanded extreme spatial precision. Evo-0 consistently outperformed state-of-the-art VLA models, even under challenging interference conditions such as:
-
Unseen distracting objects
-
Background color shifts
-
Target displacements
-
Height changes
-
Camera angle variations
In every setting, Evo-0 proved more robust and reliable.

A Step Forward for Practical Robotics
From a Western perspective, Evo-0 is a game-changer for robotics and automation. It bypasses costly sensors, cuts training overhead, and makes spatial reasoning more accessible—paving the way for smarter robots in industries like manufacturing, logistics, and even home automation.
Instead of relying on fragile depth sensors, Evo-0 builds a scalable, plug-in approach for boosting robotic intelligence. It’s a strong signal that the future of robotics will be lighter, faster, and smarter.
📄 Full research paper: Evo-0 on arXiv





