





Almost without warning, Elon Musk just swung a hammer at AI costs—slashing inference expenses by a staggering 98%.
Last Friday, xAI quietly rolled out Grok 4 Fast, a streamlined version of its flagship model designed for low-cost inference. The update uses large-scale reinforcement learning to maximize “intelligence density,” delivering benchmark results on par with Grok 4 while cutting average token usage by 40%.
According to xAI, a single inference task with Grok 4 Fast can now run at just 2% of the original cost. That’s not just a discount—it’s a potential rewrite of the large language model (LLM) competition playbook.
End-to-End Reinforcement Learning
If you had to sum up Grok 4 Fast in three keywords, they would be: AI search, massive context, and unified architecture.
In a technical blog, xAI highlighted that Grok 4 Fast comes with native tool-calling abilities, trained end-to-end via reinforcement learning. That means it knows when to trigger code execution, web browsing, or other tools to enhance results.
Thanks to the firehose of real-time data from X (formerly Twitter), the model has a major edge in autonomous exploration. Grok 4 Fast can browse the web and X seamlessly, fetch media, follow links, and integrate live data—all at lightning speed.
Benchmark results back this up:
-
BrowseComp: 44.9%
-
X Bench Deepsearch: 74%
-
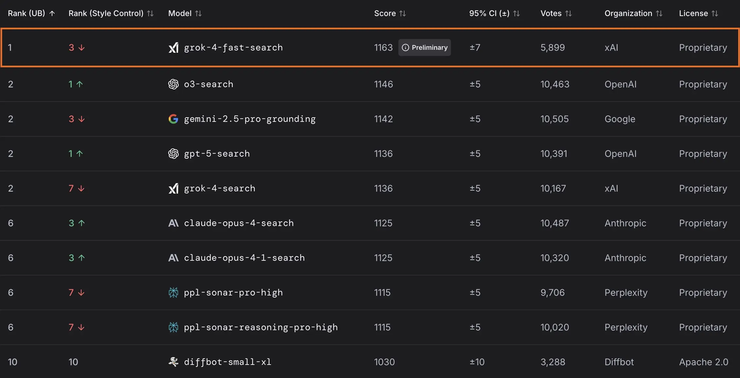
LMArena (search): Ranked #1 with 1163 points, beating OpenAI’s o3-websearch, GPT-5-search, and Grok-4-search.
-
LMArena (text): Ranked 8th, just edging out Grok-4-0709.
In short, Grok 4 Fast outperforms peers in its weight class and shows that efficiency plus reinforcement learning can rival—or even surpass—sheer parameter size.
Two Modes, One Model
Launching alongside Grok 4 Fast are two distinct modes:
-
grok-4-fast-reasoning (long chain of thought)
-
grok-4-fast-non-reasoning (rapid response)
Both feature a 2 million token context window.
The real breakthrough? A unified model architecture. Instead of toggling between separate models for reasoning vs. quick answers (the industry norm), Grok 4 Fast handles both with the same weights. Mode selection happens via system prompts.
This design cuts latency and token costs even further, pushing Grok 4 Fast closer to real-time, high-demand scenarios like chatbots, search, and customer-facing apps.
SOTA Value, Not Just Raw Power
In today’s AI market, where “state of the art” changes daily, users are less impressed by incremental benchmark gains. They care about price-to-performance.
Here’s where Grok 4 Fast shines:
-
40% higher token efficiency
-
Massive price cut per token
-
Comparable performance to Grok 4
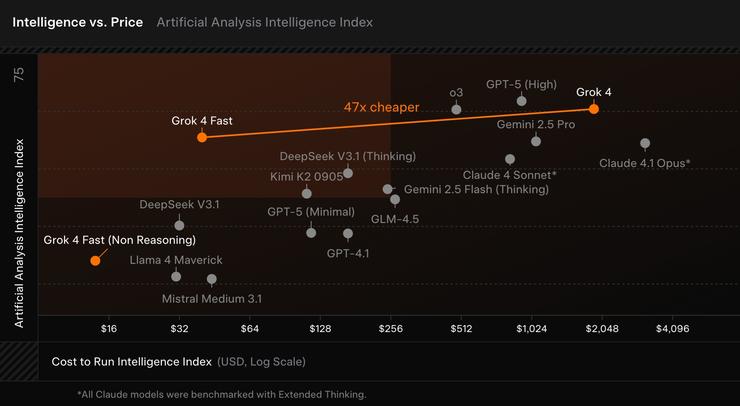


Independent tests by Artificial Analysis confirm Grok 4 Fast delivers best-in-class (SOTA) value compared to other publicly available models.
For xAI, this is less about pushing the absolute limits of intelligence and more about making “AI everyone can afford.” Musk might as well stamp “Biggest Bowl of AI for the Lowest Price” on it.
Why Cost Matters More Than Parameters
For years, the LLM race was all about bigger is better—GPT-4, Gemini, LLaMA, Grok 4 Heavy. More parameters, more compute, more power. But outside the lab, businesses and developers care about something else:
-
Inference costs
-
Response speed
-
Deployability on real hardware
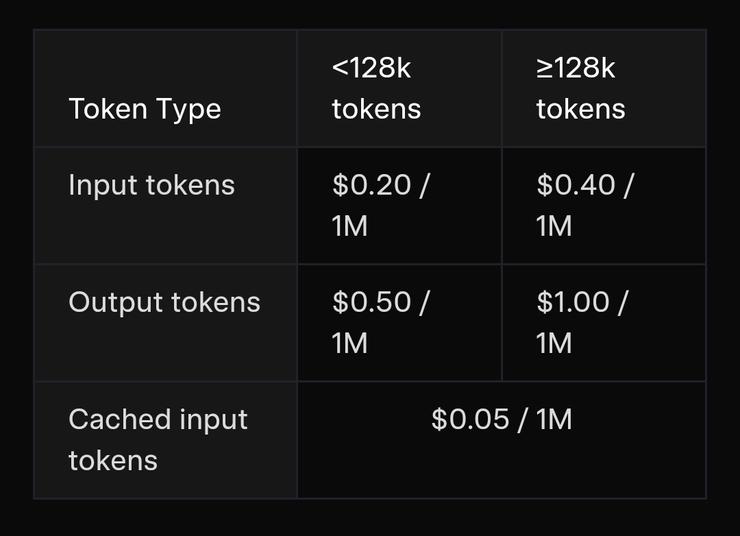
In this world, smaller, cheaper, and faster models aren’t handicaps—they’re enablers. Grok 4 Fast was likely distilled and architecture-optimized from Grok 4, reducing compute load and latency. That means it can run on lower-tier servers or even edge devices—a stark contrast to Grok 4 Heavy’s luxury-priced $3 per million input tokens and $15 per million output tokens.
In Musk’s own style, the update isn’t about being the smartest in the room—it’s about being the most usable at scale. Every token saved, every millisecond shaved off, is another step toward real-world AI adoption.
And in this battle for AI value supremacy, Grok 4 Fast just landed a knockout punch.





